

Optimization under Uncertainty in the Era of Big Data and Deep Learning: When Machine Learning Meets Mathematical Programming https://arxiv.org/ftp/arxiv/papers/1904/1904.01934.pdf
本文从现代数据视角回顾了不确定条件下优化领域的最新进展,强调了数据驱动优化的主要研究挑战和前景,它将机器学习和数学规划有机地结合起来,用于不确定条件下的决策,并讨论了潜在的研究机会。
文章首先简要回顾了用于对冲不确定性的经典数学规划技术及其在过程系统工程中的广泛应用;然后对数据驱动的分布式鲁棒优化、数据驱动的机会约束规划、数据驱动的鲁棒优化和数据驱动的基于场景的优化的相关出版物进行了全面回顾和分类。本文还确定了未来研究的丰富机会,尤其是闭环数据驱动优化框架(该框架允许从数学规划到机器学习的反馈及利用深度学习技术的基于场景的优化)。文章提出了基于在线学习的数据驱动多级优化和learning-while-optimizing方案的观点。
关键词:数据驱动优化,不确定条件下的决策,大数据,机器学习,深度学习
1.不确定条件下优化的背景
1.1随机规划
1.2机会约束规划
1.3鲁棒优化
2.不确定条件下数据驱动优化的现有方法
2.1 数据驱动的随机规划和分布鲁棒优化
2.2 数据驱动的机会受限规划
2.3 数据驱动的鲁棒优化
2.4 机会受限规划的场景优化(scenario optimization)方法
3.未来的研究方向和机会
3.1 从数学规划到机器学习的反馈“闭环”数据驱动的优化框架
3.2 利用深度学习技术对冲数据驱动优化中的不确定性
3.3 基于在线学习的数据驱动优化:一种用于解决不确定性的边学习边优化(learning-whileoptimizing)范例
4.总结
估计误差和意外干扰都会导致不确定性。不确定性问题可能会使确定性优化问题的解非最优的甚至不可行,这有时可能造成灾难性后果。 出于实际的考虑,不确定性条件下的优化受到了学术界和工业界的极大关注。
随机规划,机会约束规划和鲁棒优化是不确定性下的最典型成功优化建模范例,下面我们逐一介绍。
随机规划方法关键思想是用概率分布对不确定参数中的随机性进行建模。 通常,随机规划方法可有效适应不同时间阶段的决策过程。 在具有recourse(下面会介绍)的随机规划方法中,使用最广泛的是两阶段随机规划,其中决策被分为“here-and-now” 决策和“wait-and-see” 决策。
以下是两阶段随机规划问题的一般数学公式[J. R. Birge and F. Louveaux, Introduction to stochastic programming: Springer Science & Business Media, 2011.(为啥第一阶段是线性的呀,这限制的太死了吧)

Recourse函数Q(x,ω)定义为

其中x表示在不确定性ω实现前“here-and-now” 做出的第一阶段决策,而第二阶段决策y在观察到不确定性实现后以“wait-and-see” 的方式被推迟。 两阶段随机规划模型的目标包括两部分:第一阶段目标c^Tx和第二阶段目标b(ω)^T y(ω)的期望。
与第一阶段决策相关的约束为Ax≥ d, x∈X,而第二阶段决策的约束为
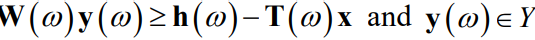
集合X和Y可以包括非负性,连续性或可积性限制。
随着场景数量增加,计算时间增加,两阶段随机规划问题在计算上比较昂贵。 为此,研究者已经开发了包括Benders分解、L-shaped方法和Lagrangean分解在内的基于分解的算法。 二进制决策变量的位置对于计算算法的设计至关重要。 对于具有整数recourse的随机规划,recourse函数的期望不再凸,甚至不连续,这阻碍了常规L-shaped方法的使用。 结果,研究者发明了拉格朗日松弛、分支定界法和改进的L- shaped方法来有效求解两阶段随机混合整数规划。
随机规划在批处理设计和操作、工艺流程图优化、能源系统和供应链管理等方向有广泛应用。 由于其广泛的适用性,研究者钻研了关于它的大量变体,如通过使用场景树可以轻松将(1)中两阶段公式扩展为多阶段随机规划设置。 其他扩展包括随机非线性规划X. Li, A. Tomasgard, and P. I. Barton, "Nonconvex Generalized Benders Decomposition for Stochastic Separable Mixed-Integer Nonlinear Programs(还要可分,可惜了)," Journal of Optimization Theory and Applications, vol. 151, pp. 425-454, 2011.和具有内生不确定性的随机规划[60]V. Gupta and I. E. Grossmann, "A new decomposition algorithm for multistage stochastic programs with endogenous uncertainties," Computers & Chemical Engineering, vol. 62, pp. 62-79, 2014.[61]V. Goel and I. E. Grossmann, "A Class of stochastic programs with decision dependent uncertainty," Mathematical Programming, vol. 108, pp. 355-394, 2007.
关注公众号”黄含驰的机器学习与优化打怪路“(微信号:AIORHHC),任意转发一则主篇文章至朋友圈或200+群聊,添加我微信jjnuxjp5x,即可获取我这几天悉心整理和重构的优化 / 强化学习/数学学习大礼包。
转发n(n=1,2,3)条则可领取n个方向的大礼包喔~
作为不确定性条件下优化的另一种强大范式,机会约束规划旨在优化目标,同时确保在不确定性环境中以指定概率满足约束条件A. Prékopa, "Stochastic programming, volume 324 of Mathematics and its Applications," ed: Kluwer Academic Publishers Group, Dordrecht, 1995。 与随机规划方法一样,概率分布是捕获机会受限优化中不确定参数随机性的关键不确定性模型。 机会受限规划最初是在A. Charnes and W. W. Cooper, "CHANC的开创性工作中引入的,此后引起了相当多的关注。 这种机会约束或概率约束足够灵活,可以量化目标性能和系统可靠性间的权衡Chance constrained programming approach to process optimization under uncertainty。
机会约束优化问题的一般表示如下:

其中x表示决策变量的向量,X表示确定性可行区域,f是要最小化的目标函数,ξ是遵循已知概率分布且具有支持集Ξ的随机向量, 表示约束映射,0是全零向量,参数ε是预先指定的风险级别。
机会约束 保证决策x以至少1-ε的概率满足约束。 注意,当约束数m = 1时,上述优化模型是单个机会约束规划。 对于m> 1,它被称为联合机会约束规划CHANCE CONSTRAINED PROGRAMMING WITH JOINT CONSTRAINTS。 机会受限规划的一个显着优点是允许决策者选择自己的风险水平来改善目标。 为对顺序决策过程进行建模,最近[66,67]研究了应用广泛的带有recourse的两阶段机会约束优化方法。
[66]X. Liu, S. Kucukyavuz, and J. Luedtke, "Decomposition algorithms for two-stage chanceconstrained programs," Mathematical Programming, vol. 157, pp. 219-243, 2016.
[67]M. A. Quddus, S. Chowdhury, M. Marufuzzaman, F. Yu, and L. K. Bian, "A two-stage chance-constrained stochastic programming model for a bio-fuel supply chain network," International Journal of Production Economics, vol. 195, pp. 27-44, 2018.
尽管建模能力强大,但由于以下两个主要原因,机会受限规划通常在计算上难以处理。①计算给定x的约束满足的概率涉及多元积分,这在计算上让人难受。 ②对于不确定矢量ξ的任何实现,即使集合X凸且G(x,ξ)在x中凸,可行域也不凸[62]。 鉴于这些计算难题,大量相关文献致力于攻克机会受限的优化问题,如样本平均逼近[68],顺序逼近[69]和凸保守逼近方案[70]。 请注意,在某些非常特殊的情况下,机会受限规划会采用凸重构。 例如,个体机会受限规划被赋予正态分布的易于处理的凸重构[32]。 如果不确定参数独立,则具有右侧不确定性的机会约束是凸的,并遵循对数-凹面分布[62]。
鲁棒优化不需对不确定参数的概率分布有准确了解[87-89]。 相反,它使用不确定性集(包括可能的不确定性实现)对不确定性参数进行建模。 值得注意的是,不确定性集是鲁棒优化框架中最重要的因素[89]。 给定特定的不确定性集,鲁棒优化的想法是对冲不确定性集内的最坏情况。 最坏情况的不确定性实现是根据不同上下文定义的:它可能是引起最大约束冲突的实现,导致最低资产收益的实现[90]或导致最高遗憾的实现[91]。
传统的盒不确定性设置并不是好选择,因为它包含不太可能发生的情况,其中不确定性参数可能同时增加到其最高值。 常规的盒不确定性集定义如下[92]

其中Ubox是盒不确定性集合,u是不确定参数的向量,ui是其第i个分量。 ui ^L和ui ^U分别表示不确定参数ui的下限和上限。 盒不确定性集仅定义向量u中每个不确定参数的范围。 一个人不能轻易控制这种不确定性的大小来满足他/她规避风险的态度。 为此,研究者提出了以下budgeted uncertainty set[88]
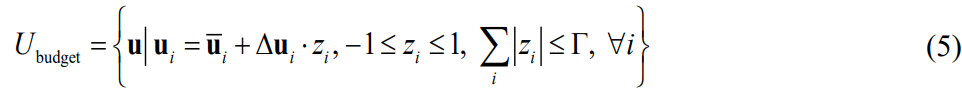
其中Ubudget表示budgeted uncertainty set,u和ui与(4)中定义相同, 是ui的名义值,?ui是不确定性参数ui的最大可能偏差,zi表示参数偏差的程度和方向 ,Γ是不确定性预算。
传统的(主要是静态)鲁棒优化方法可以一次做出所有决策。 这种建模框架不能很好地代表顺序决策问题[94-96]。Adjustable robust solutions of uncertain linear programs 提出了自适应鲁棒优化(ARO),通过结合求助决策为不确定性下的优化提供了新范式。 由于观察到不确定性实现后调整recourse决策的灵活性,ARO通常比静态鲁棒优化生成的保守解少。 两阶段自适应鲁棒混合整数规划模型的一般形式如下:
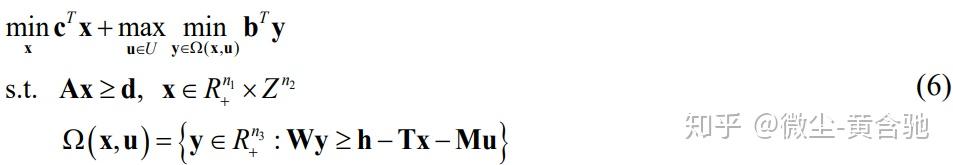
其中x是在不确定性u实现前做出的第一阶段决策,而第二阶段决策y以“wait-and-see”方式推迟。 x包括连续和整数变量,而y仅包括连续变量。 c和b是成本系数的向量。 U是代表不确定性实现区域特征的不确定性集。 ARO方法可用于解决各种应用中的不确定性,如流程设计[99-101],流程调度[102],供应链优化[101、103]等。
除了两阶段ARO框架,多阶段ARO方法由于其独特特征可反映随时间推移不确定性的连续实现而引起极大关注[104]。 在多阶段ARO中,决策是按顺序进行的,不确定性分阶段逐步揭示。 注意,ARO在静态鲁棒优化上提供的附加价值是其基于不确定性实现的recourse决策的可调整性[97]。[105,106]已经详述了多级ARO方法在过程调度和规划中的应用。
与传统的数学规划技术不同,数据驱动的方法不会假定不确定性模型是先验的,相反将它们全部集中在只有不确定性数据可用的实际设置上。
本节首先介绍这种新兴的不确定性范式在数据驱动优化中的动机,然后提出其模型,在此建模范例中,不确定性是通过一系列概率分布来建模的,这些概率分布被称为模糊集,可以很好地捕获手头的不确定性数据。 再然后,本节介绍并分析9种类型的模糊集以及它们各自优缺点。 最后,本节还将讨论将DRO扩展到多阶段决策环境及其在Process Systems Engineering(PSE)中的最新应用。
实际生产中决策者拥有的是一组历史/实时不确定性数据,数据概率分布无法事先就确定好。常规随机规划中的假定概率可能会偏离真实分布。 因此,依靠单一概率分布可能导致解决方案欠佳,甚至导致样本外性能下降。 由于随机规划的这些弱点,DRO作为一种新的数据驱动优化范例应运而生,该范例可对付最模糊情况下的模糊集。 DRO方法没有假设单一的不确定性分布,而是从不确定性数据中通过统计推断和大数据分析构建一个概率分布的不确定性集。这样一来,DRO就能对冲分布误差,并考虑不确定性数据的输入。
数据驱动随机规划的一般模型表示如下[114]

其中x是决策变量的向量,X是可行集,l是目标函数,ξ表示随机向量,其概率分布仅已知位于模糊集 D中。 DRO方法旨在在最坏情况下进行最佳决策,从而为整个分布族提供性能保证。
与传统随机规划方法相比,DRO或数据驱动的随机优化框架具有两个突出优点。 首先,它允许决策者将从不确定性数据中学到的部分分布信息整合到优化中。 结果,数据驱动的随机规划方法极大减轻了优化器的诅咒问题,并提高了样本外性能。 其次,数据驱动的随机规划设计从鲁棒优化中继承了可计算性,并且可在多项式时间内准确解决某些由此产生的问题,而无需借助采样或离散化的近似方案。例如,事实证明,对于变量连续和具有基于矩的模糊集 的凸规划的优化问题(7)可在多项式时间内得到解决[114]。
模糊集的选择在DRO的性能中至关重要。 选择模糊集时,决策者需考虑易处理性,统计意义和性能三个因素[115]。 首先,具有模糊集的数据驱动随机规划问题应在计算上易于处理,这意味着可将最终的优化公式化为线性,圆锥二次或半定规划。 其次,导出的模糊集应具有明确的统计意义。 因此,[114、116、117]广泛研究了基于不确定性数据构造模糊集的各种方法。 第三,为提高结果决策性能,设计的模糊集应该是紧密的。
一种构造模糊集的常用方法是基于矩的方法,[118]使用统计推断从不确定性数据中提取一阶和二阶信息。 指定支持集,一阶、二阶信息的模糊集如下所示:
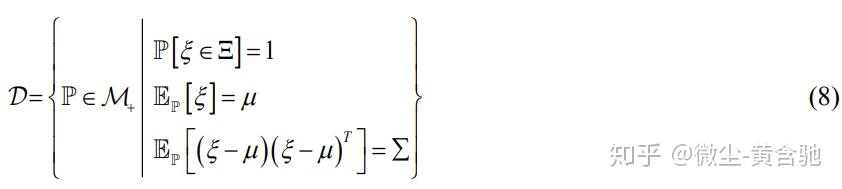
其中ξ表示不确定性矢量,Ξ是支持集,P表示ξ的概率分布,M+表示所有概率度量的集合,E_P表示对分布P的期望。 参数μ和Σ分别表示从不确定性数据估计的平均矢量和协方差矩阵。
(8)中设置的模糊无法解释均值和协方差矩阵也存在不确定性的事实。 为此,[114]基于分布的支持集信息及均值和二阶矩阵的置信区域提出了模糊集。 由此产生的DRO问题可在多项式时间内得到有效解决。
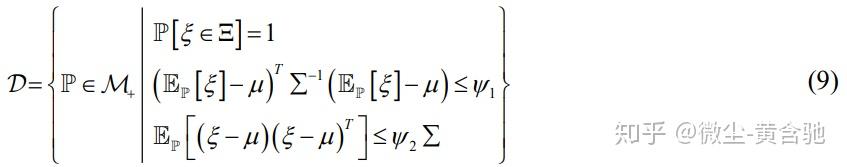
其中ξ表示不确定性矢量,Ξ是支持度,P表示ξ的概率分布。 等式约束强制所有不确定性实现都位于支持集Ξ中。 参数ψ1和ψ2用于分别定义一阶矩和二阶矩信息的置信区域的大小。基于矩的模糊集通常具有“计算可处理”的优势。
比如,[117]开发了具有基于主成分分析和一阶偏差函数的模糊集的DRO ,并且通过过程网络计划和批生产计划证明了这种数据驱动DRO方法的计算效率。 最近,[119]开发了一种为优化页岩气供应链设计和运行的数据驱动的DRO模型,以应对与页岩气估计的最终采收率和产品需求相关的不确定性。 但是,当不确定性数据量达到无穷大时,一般方法不能保证基于矩的模糊集会收敛到真实概率分布。 因此,这种类型的模糊集受到具有中等不确定性数据的保守性的困扰。 为解决基于矩的方法的上述问题,研究者开发了基于概率分布间统计距离的模糊集,如下所示

其中P是不确定参数的概率分布,, 0表示参考分布如经验分布,d表示两分布间的一些统计距离,θ表示置信度。
可基于采用的距离度量(如Kullback-Leibler散度和Wasserstein距离)进一步分类(10)中的“模糊”。 例如,针对批量问题,[121]提出了一种将卡方拟合优度检验和鲁棒优化相结合的DRO模型。 需求的模糊集是通过使用统计中的假设检验(卡方拟合优度检验)从不确定性数据中构建的。 该集合可由线性约束和二阶圆锥约束很好地定义。 值得注意的是,他们模型的输入是直方图,所以我们可使用有限维概率向量来表征分布。 采用的统计量属于phi散度,这促使研究者如[122]通过使用phi散度来构造分布不确定性。
为说明顺序决策过程,研究人员最近通过合并recourse决策变量开发了自适应DRO方法[123,124]。 通用的两阶段数据驱动随机规划模型如下所示:

其中x表示观察不确定性实现前需要确定的第一阶段决策变量的矢量,y表示可根据实现的不确定性参数ξ进行调整的第二阶段决策变量的矢量,集合X和Y可以包含非负性 ,连续性或完整性约束,并且Q表示recourse函数。 上述数据驱动的随机规划的目的是针对模糊集D中所有可能的不确定性分布最小化最坏情况的预期成本。 根据诸多文献,多阶段数据驱动的DRO正在成为快速发展的研究方向。
与传统的随机规划方法相比,数据驱动的随机规划有几个明显的优点。 随着数据驱动的随机规划的日益普及,DRO作为一种新的数据驱动的优化范例而出现,它可对付模糊集中的最坏情况,并在电力系统中有诸多细分应用场景,如单位承诺问题[125-128]和最佳功率流[129,130]。
关注公众号”黄含驰的机器学习与优化打怪路“(微信号:AIORHHC),任意转发一则主篇文章至朋友圈或200+群聊,添加我微信jjnuxjp5x,即可获取我这几天悉心整理和重构的优化 / 强化学习/数学学习大礼包。
转发n(n=1,2,3)条则可领取n个方向的大礼包喔~
与2.1中讨论的数据驱动的随机规划方法相比,数据驱动的机会受限规划是另一种范式,重点关注最坏情况概率下的机会约束满足,而不是优化最坏情况下的期望目标。 尽管数据驱动的机会受限规划和DRO在不确定性模型中都采用了模糊集,但它们具有不同的模型结构。 具体来说,数据驱动的机会约束规划的特点是受概率分布不确定性的约束,而DRO通常只涉及目标函数对一个概率分布族的最坏情况期望。正如上文的介绍,机会受限规划方法假定完全了解分布信息。但是,决策者只能访问有限数量的不确定性实现或不确定性数据。 一方面,这种分布的完整知识通常从有限数量的不确定性数据中估计,或者从专家知识中规划。 另一方面,即使概率分布可用,机会受限规划在计算上也很麻烦。 在实践中,我们只能获得关于不确定性概率分布的部分信息。 因此,在大数据时代,数据驱动的机会约束优化成为对冲不确定性的另一范式(逻辑有点怪)。
数据驱动机会受限规划的一般形式为
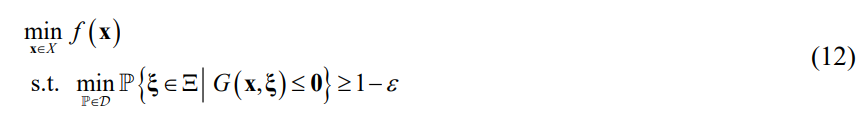
其中x表示决策变量的向量,X表示确定性可行区域,f是目标函数,ξ是服从属于模糊集的概率分布P的随机向量。 表示约束映射,0是全零向量,参数ε是预先指定的风险级别。 数据驱动的机会约束强制执行模糊集内每个概率分布的经典机会约束。
最终数据驱动机会受限规划的计算可处理性可能会因为模糊集和优化问题的不同结构而有所不同。 在下文中,我们根据具有不同分布和优化结构的不确定性集来总结相关论文。
由所有共享相同已知均值和协方差的分布组成的模糊集下的分布鲁棒的个体线性机会约束被On distributionally robust chance-constrained linear programs重新表述为凸的二阶锥约束。该论文在(a)具有box support的独立随机变量和(b)在正交support上的径向对称非递增分布的分布族下,提供了执行分布鲁棒机会约束的确定性凸条件。假设一阶、二阶矩,Distributionally robust joint chance constraints with second-order moment information研究了分布鲁棒联合机会约束的最坏情况条件风险值(CVaR)近似,所得保守近似可被铸成半正定规划。除矩信息外,"Ambiguous risk constraints with moment and unimodality information在模糊性集合中还加入了一种特殊的分布结构信息——单模性,并将相应模糊风险约束重构为一组二阶锥约束。最近Data-Driven Robust Chance Constrained Problems: A Mixture Model Approach利用基于混合分布的模糊性集,采用固定分量分布和不确定混合权重的混合分布(而没有假设分布的非正态性),开发了数据驱动的稳健个体机会约束规划以及凸近似。
粗糙翻译--
在现实世界的应用中,精确的矩信息的获取是具有挑战性的,只能通过不确定性实现的置信区间来估计[114]。为了适应这种矩的不确定性,在分布稳健的机会约束方面进行了尝试,包括构造凸矩模糊性集[134]、采用具有二阶矩约束的Chebyshev模糊性集[135]、表征具有均值和协方差上界的分布族[136]。研究了模糊联合偶然性约束,其中模糊集的特征是均值、凸支持和离散度的上界[137],所得到的约束对于右手边的不确定性是可圆锥表示的。除了广义矩约束[138],分布的结构特性,如对称性、单模性、多模性和独立性,也被进一步整合到利用Choquet表示法[115]的分布稳健机会约束程序中。在均值和方差[139]、凸矩约束[140]、均值绝对偏差[141]和混合分布[142]定义的模糊性集下,对分布稳健的机会约束进行了非线性扩展。
虽然基于矩的模糊性集取得了一定的成功,但随着可用不确定性数据数量的增加,它们并不能收敛到真实的概率分布。因此,所产生的数据驱动的偶然性约束程序往往会产生保守的解。为此,提出了具有基于距离的模糊集的数据驱动机会约束程序,以缓解基于时刻的数据驱动机会约束程序的不良后果。将Prohorov度量定义的模糊性集引入到分布式鲁棒集合约束中,并利用鲁棒抽样问题对所得优化问题进行了逼近[143]。在Kullback-Leibler散度方面,模糊集包含所有接近参考分布的分布的分布稳健机会约束被投为调整风险水平的经典机会约束[120]。提出了基于?-分歧的模糊性集的数据驱动机会约束程序[144],并利用内核平滑法进行了进一步的扩展[22]。
尽管基于矩的歧义集取得了一定的成功,但随着可用不确定性数据数量的增加,它们并没有收敛到真实的概率分布。 因此,结果数据驱动的机会受限程序往往会产生保守的解决方案。 为此,提出了基于距离的歧义集的数据驱动的机会受限程序,以减轻基于矩的数据驱动的机会受限程序的不良后果。 由Prohorov度量定义的歧义集被引入到分布稳健的机会约束中,并且通过使用稳健的采样问题来近似结果优化问题[143]。 具有歧义集的分布鲁棒机会约束被包含为经过调整的风险水平的经典机会约束,其中歧义集包含所有与Kullback-Leibler散度相近的参考分布。 提出了基于?-散度的模糊集的数据驱动机会受限程序[144],并使用核平滑方法进行了进一步扩展[22]。
近来,数据驱动的Wasserstein球的机会约束被精确地重新表述为混合整数圆锥约束[145,146]。 利用强对偶结果[147],研究了具有Wasserstein模糊度集的分布鲁棒机会受限程序,以解决带有左右手不确定性的线性约束[148]以及一般非线性约束[149]。
数据驱动的机会受限规划在许多领域都有成功的应用,例如电力系统[150],随机控制[151]和车辆路径问题[152]。
作为鲁棒优化的最重要因素,不确定性集会内生地确定鲁棒最优解,因此应格外小心。 然而,在不提供足够灵活性来捕获不确定性数据的结构和复杂性的情况下,通常用固定形状和/或模型来预先设置常规鲁棒优化方法中的不确定性集。 例如,不确定性集(4)(5)中的几何形状不会随不确定性数据的固有结构和复杂性而变化。 此外,这些不确定性集由有限数量的参数指定,从而建模灵活性有限。受此驱使,数据驱动的鲁棒优化成为解决决策不确定性的强大范例。
C. Ning and F. You, "Data-Driven Adaptive Nested Robust Optimization: General Modeling Framework and Efficient Computational Algorithm for Decision Making Under Uncertainty," AIChE Journal, vol. 63, pp. 3790-3817, 2017提出了一种利用Dirichlet过程混合模型功能的数据驱动的ARO框架。 基于贝叶斯机器学习的数据驱动方法用于定义不确定性集。 然后,机器学习模型通过四级优化框架与ARO方法集成。 此框架有效解决了不确定性数据的相关性,不对称性和多模式问题,因此保守性较差。其显着特征是使用多个基本不确定性集来提供不确定性的高保真度描述。 尽管数据驱动的ARO很吸引人,但它并不能说明决策中的遗憾度(regret)。受此驱使,C. Ning and F. You, "Adaptive robust optimization with minimax regret criterion: Multiobjective optimization framework and computational algorithm for planning and scheduling under uncertainty," Computers & Chemical Engineering, vol. 108, pp. 425-447, 2018开发了一种数据驱动的双准则ARO框架以有效解释传统的鲁棒性以及最小最大遗憾~
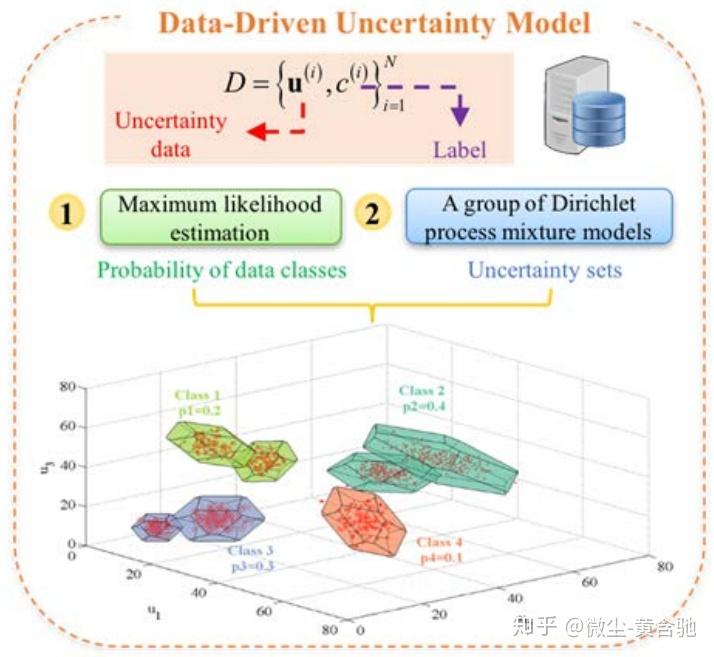
在某些应用中,大型数据集中的不确定性数据通常是在多种条件下收集的。 Data-driven stochastic robust optimization: General computational framework and algorithm leveraging machine learning for optimization under uncertainty in the big data era提出了一种数据驱动的随机鲁棒优化框架,用于利用标记的多类不确定性数据进行不确定性下的优化。 机器学习方法(包括Dirichlet过程混合模型和最大似然估计)用于不确定性建模,如图1所示。该框架是通过双层优化结构基于数据驱动的不确定性模型进一步提出的。 外部优化问题遵循两阶段随机规划方法,而ARO被嵌套为维持计算可处理性的内部问题。
为了减轻计算负担,一些研究如Data-driven decision making under uncertainty integrating robust optimization with principal component analysis and kernel smoothing methods干脆基于机器学习技术(例如主成分分析和支持向量聚类)的凸多面体数据驱动不确定性集合,开发了一种数据驱动的鲁棒优化框架,该框架利用主成分分析和核平滑的能力在不确定性条件下进行决策。 这种方法可有效捕获不确定参数间的相关性,并通过主成分分析来识别潜在的不确定性来源。 为解决不对称分布问题,在不确定性集中使用前向和后向偏差矢量,并将其与鲁棒优化模型进一步集成。 Data-driven robust optimization based on kernel learning提出了一种基于支持向量聚类的数据驱动的静态鲁棒优化框架,该框架旨在找到最小体积的超球面以封装不确定性数据。 其采用的分段线性核结合了协方差信息,从而有效地捕获了不确定性之间的相关性。 这两种数据驱动的鲁棒优化方法利用了从数据中学到的多面体不确定性,从而享有计算效率。
基于统计假设检验]D. Bertsimas, V. Gupta, and N. Kallus, "Data-driven robust optimization," ,copula (Data-driven robust optimization under correlated uncertainty: A case study of production scheduling in ethylene plant (Reprinted from computers and Chemical Engineering, vol 109, pg 48-67, 2017))和概率密度轮廓Data-driven rolling-horizon robust optimization for petrochemical scheduling using probability density contours,开发了各种类型的数据驱动不确定性集用于静态鲁棒优化。
为解决不确定性下的多级决策问题,A data-driven multistage adaptive robust optimization framework for planning and scheduling under uncertainty开发了一种基于数据驱动的不确定性下基于多级ARO和非参数核密度估计的优化方法。 该框架的显着特征是结合了分配信息,以解决过度保守的问题。采用鲁棒核密度估计从数据中提取概率分布。此数据驱动的多阶段ARO框架利用强大的统计数据以对数据异常值免疫。 为解决由此产生的数据驱动的ARO问题,框架开发了一种精确鲁棒的counterpart。
近年来,数据驱动的鲁棒性优化已应用于各种领域,例如电力系统[160],能源系统[161],计划和调度[106、158],过程控制[156、162]和 运输系统[163,164]。
基于场景的优化的显着特征是它不需要像随机规划方法那样的明确的概率分布知识。 另外,基于场景的优化使用不确定性场景来寻求具有高概率保证约束满足的最优解,而不是像在随机编程中那样使用场景或样本来近似期望项。 尽管基于场景的优化可看作是具有离散不确定性集(包括不确定性数据)的鲁棒优化的一种特殊类型,但它可以为测试数据集中那些未观察到的不确定性数据提供概率保证。 请注意, 基于场景的优化方法是不确定性框架下的常规数据驱动优化,与其他数据驱动的优化方法相比,不确定性数据或随机样本的使用更为直接。这种数据驱动的优化框架最早是[165]提出的,并在系统和控制界[166]中得到极大的普及。与数据驱动的机会约束规划一样,场景优化不需知道真实的底层不确定性分布,而需要有限数量的不确定性实现。具体来说,场景方法通过N个独立、均匀分布的不确定性数据u(1),…,u(N)来强制约束满足。由此产生的情景优化问题由以下公式给出。
[165]G. Calafiore and M. C. Campi, "Uncertain convex programs: randomized solutions and confidence levels," Mathematical Programming, vol. 102, pp. 25-46, 2005.
[166]M. C. Campi, S. Garatti, and M. Prandini, "The scenario approach for systems and control design," Annual Reviews in Control, vol. 33, pp. 149-157, 2009.

通常假设函数f关于x凸,且和u之间可以是任意的非线性依赖。当不确定性集构造为u(1),…,u(N)的并集时,基于场景的优化可视为数据驱动的鲁棒优化的特例。
在场景优化文献中, 称为从乘积概率空间中提取的多样本或场景。 由于多样本的随机性,用x *(ω)表示的场景优化问题(13)的最优解也是随机的。 场景方法的一个主要优点是场景优化问题与确定性问题的问题类型相同,因此当f(x,u)关于x凸时,可通过凸优化算法有效地解决。 而且,最优解x *(ω)保证以高概率满足其他从未见过的不确定性实现的约束The Exact Feasibility of Randomized Solutions of Uncertain Convex Programs。
……
传统上,场景优化领域主要关注于凸优化问题,其中support constraints 的数量是由决策变量数决定的上界。然而,这种上界在非凸场景优化问题中已不存在,这就给将场景理论扩展到非凸环境的研究带来挑战。目前很少有作品使用场景方法考虑非凸不确定规划。不过A General Scenario Theory for Nonconvex Optimization and Decision Making提出了通过支持子样本的概念,以等待判断的方式评估最优解的泛化。该方法可用于一般的非凸设置如混合整数方案优化问题。另一种解决非凸场景优化的尝试是Randomized Strategies for Probabilistic Solutions of Uncertain Feasibility and Optimization Problems,文章利用统计学习理论对违规概率进行约束,并设计了一种随机化解算法。基于统计学习理论的方法为所有可行解提供了概率保证,而convex scenario方法则不同,其保证只对最优解有效。基于统计学习理论的方法对所有可行解提供概率保证的这一独特特征具有实际意义(Research on probabilistic methods for control system design),因为求解非凸优化问题达到全局最优在计算上很有挑战性。A Scenario Approach for Non-Convex Control Design最近研究了一类非convex scenario优化问题,它具有非凸目标函数和凸约束条件。由于这类非convex scenario规划最优解的Helly维度可能无界,因此,我们不大可能直接应用基于Helly定理的场景方法。为了攻克该难点,"The Exact Feasibility of Randomized Solutions of Uncertain Convex Programs将可行域限制在少数优化器的凸壳内,从而使样本复杂度的最新成果结果得以应用。
本节重点介绍不确定条件下数据驱动优化的一些有前途的研究方向。 我们特别关注一些有关闭环数据驱动的优化,深度学习与基于场景的优化的集成以及边学习边优化框架的思想。
不确定性下的数据驱动优化框架可被视为“混合”系统,该系统集成了基于机器学习的数据驱动系统以从数据中提取有用和相关的信息,以及基于数学规划的基于模型的系统。 现有的数据驱动优化方法采用顺序和开环方案,这可通过引入从基于模型的系统到数据驱动系统的反馈步骤来进一步改进。 探索信息反馈以完全结合上游机器学习和下游数学规划的“闭环”数据驱动优化范例可能是一种更有效,更严格的方法。
3.1.1常规的“开环”数据驱动优化方法的问题
现有的数据驱动优化框架大多以顺序的方式分别处理由数据驱动的系统和基于模型的系统执行的任务:数据充当数据驱动系统的输入, 数据驱动系统提取有用准确且相关的不确定性信息,并进一步传递到基于数学规划的基于模型的系统,以便在不确定性下使用鲁棒优化和随机规划等范式进行严格和系统的优化。 但是,由于这两系之间的顺序连接,机器学习模型在不与“下游”数学规划交互的情况下进行了训练。 因此,从控制理论的角度来看,现有数据驱动的优化文献中的此类“混合”系统实质上是开环的。 与开环系统相比,使用反馈控制策略的闭环系统在科学和工程学的几乎每个领域(例如生物系统,社交网络)都有惊人的优越系统性能(如稳定性,对干扰的鲁棒性和安全性)。 因此,除了从机器学习结果输入到数学规划问题中的信息流外,我们还应有一个“反馈”通道,用于信息流从基于模型的系统返回到数据驱动的系统。 从数学规划到机器学习的这种反馈回路的设计值得在未来研究中得到进一步关注。 尽管在强化学习中有闭环机器学习方法Multi-timescale, multi-period decision-making model development by combining reinforcement learning and mathematical programming,但总体来讲在不确定性下为数据驱动的数学规划开发闭环策略的工作很少。
3.1.2 一个“闭环”数据驱动的优化框架
由于其在机器学习模型训练中的关键作用,损失函数可为考虑未来工作中的反馈步骤提供基础。不使用逻辑斯蒂或平方误差损失这些与数学规划无关的损失函数,而使用结合了数学规划目标函数的损失函数来训练机器学习模型。 特别地,数学规划问题中常规损失函数和目标函数的加权和在处理当前“开环”数据驱动框架遇到的问题时应该很有用。 机器学习和数学规划间的迭代方案为封闭数据驱动系统和基于模型的系统的环路提供了另一种有希望的途径。 图2给出了闭环数据驱动数学规划系统的潜在原理图。 从图中可看到,来自基于模型的系统的反馈充当了数据驱动系统的输入。 通过这种方式,“混合”系统成为一个闭环系统,可在两相反方向上传输信息。这种反馈策略应有益于“混合”系统,并可提供将机器学习和数学规划有机集成的有效方式。

研究挑战来自“混合”系统的反馈步骤。 在典型的PSE应用中,数学规划的问题规模往往很大。 这种与大数据结合的大规模数学规划问题可能会给机器学习的训练带来计算挑战。 此外,如何设计有效的反馈策略来 "闭环",是另一个需要解决的关键挑战。
4.1.3 将“先验”知识整合到数据驱动的优化框架中
除不确定性数据外,某些可用的特定领域知识或“先验”知识也可作为数据驱动系统的另一信息输入。 仅依靠数据来开发不确定性模型可能会对下游的数学规划产生不利影响。 先验知识描述了决策者对不确定性的了解,并可能以不同的形式出现。 例如,先验知识可以是概率分布的结构信息,不确定参数的上下限或不确定性间的某些相关关系。 在数据驱动的优化框架中整合此类“先验”知识可能会非常有用,且在面对混乱数据时可以提供更可靠的结果。
最近,深度学习由于在数据的分层表示中具有惊人威力I. Goodfellow, Y. Bengio, A. Courville, and Y. Bengio, Deep learning vol. 1: MIT press Cambridge, 2016.[16]I. E. Grossmann而展示出其广阔前景。 在实际应用中,不确定性数据表现出非常复杂且高度非线性,因此,探索利用各种结构的深度神经网络来发现不确定性数据的有用模式进行数学规划的潜在机会应该很有前途。
3.2.1 可利用深度RNN和LSTM等技术来解密不同时间段的时间动态和不确定性轨迹。
3.2.2 基于场景优化的深层生成模型
尽管基于场景的优化有各种成功的应用,但这种数据驱动的优化框架有其自身局限性。一般情况下无论概率类型如何,基于场景的优化通过约束抽样享受计算效率,并提供可行性保证。其优势很大程度上依赖于一个关键假设,即有足够多的不确定性数据可用。然而,在大多数情况下此假设并不成立,从底层真实分布中抽样得到的不确定性数据量是相当有限的。此外,在某些特定情况下,获取不确定性数据可能非常昂贵或耗时,这大大阻碍了基于场景的方法的适用性。处理数据量不足的实际挑战需要得到进一步的研究关注,期待未来开发解决这一问题的基于数据驱动的场景优化框架。

目前,我们可以试着通过利用深度生成模型的强大功能来填补基于数据的基于场景的优化,如图3所示。可利用深度生成模型,而不是假设从真实分布中采样的无限不确定性场景,从现有不确定性数据中学习内在的有用模式,并生成合成数据。这些由深度学习技术生成的合成不确定性数据模仿了真实的不确定性数据,在基于场景的优化模型中应该是潜在有用的。可以利用深度生成模型来生成合成不确定性数据,目的是为了在不确定性数据不足的情况下更好地进行决策。更准确地说,在深度生成模型中,真实的数据分布被显式或隐式地学习,然后利用学习到的分布生成新的数据点,称为合成数据。最常用的深度生成模型之一是变分自编码器(VAEs)[15]。VAEs通过以无监督方式合成一个编码器网络和一个解码器网络的架构来生成新的数据样本。编码器的功能是降维并提取潜伏特征,而解码器网络的目的是重建给定潜伏变量的数据。通过这种方式,VAE模型通过最大化数据对数似然的下界来学习复杂的目标分布。这种技术的优点是,其质量很容易通过对数似然或重要性抽样来评估。
然而,研究人员发现VAEs通常倾向于生成模糊图,这意味着真实分布与学习的分布间存在明显差异[15]。最近,一种名为生成式对抗网络(GANs)的新兴深度生成模型被提出,并在图像处理[206]、可再生场景生成[207]和分子设计[208]等各领域越来越受欢迎。与VAE不同的是,GANs通过两个竞争性神经网络,即生成器网络和判别器网络[209]间的零和博弈来隐式学习数据分布。给定噪声输入,生成器网络通过生成可信的合成数据与判别器网络竞争。相反,判别器网络试图将真实的不确定性数据与合成数据区分开来。这两个网络相互竞争。相应地,一旦达到纳什均衡,生成器网络所产生的数据分布将是真实分布。随机凸规划所需的样本量与决策变量的数量呈线性scale[181],这意味着 "小数据 "机制应该是大规模优化问题经常遇到的。
……
对于决策变量数巨大、风险水平值较小的优化问题,保证约束条件所需可样本量能会很大[181]。因此,可用的不确定性数据量可能不足以达到满足概率保证的目的。然而,不确定性数据量仍可满足训练生成模型的需要。
在许多实际环境中,不确定度数据是以在线方式依次收集的S. Shalev-Shwartz, "Online learning and online convex optimization," 。虽然之前的工作已探索了不确定性集的在线学习A data-driven robust optimization approach to stochastic model predictive control,但它们通常会利用现有的和新增的数据从头开始重新训练数据驱动系统,所以这些方法只适用于具有缓慢动态的系统。因此,到目前为止,很少有研究攻克具有快速动态的系统的实时数据分析。
未来我们可以利用深度强化学习的优势,探索边学习边优化的方案。一方面,不确定性模型应该是时变的,以适应实时的不确定性数据。另一方面,在不确定性下依次决策,做出决策后,不确定性被实现且被存储到数据库中。此框架存在以下挑战:a.以在线方式更新的挑战;b.基于在线学习的数学规划问题的计算挑战;c.对数据质量要求的挑战。此外还有一些理论研究上的挑战,比如研究当概率分布变化时解的收敛性。
虽然传统的随机规划、鲁棒优化和机会约束优化是公认的对冲不确定性的建模范式,但可预见的是,在不久的将来,数据驱动数学规划框架将在大数据和深度学习的推动下迎来快速发展。本文从系统化的不确定性建模、机器学习与数学规划的有机结合、解决所产生的数学规划问题的高效计算算法等方面回顾了不确定性下数据驱动数学规划的最新进展。同时详细分析了不同数据驱动的不确定性模型的优缺点。未来的研究方向可以是设计反馈步骤以闭合数据驱动系统和基于模型的系统,利用深度生成模型进行基于数据驱动的场景优化,以及开发具有实时数据在线学习的数据驱动数学规划框架。





